Using Quora questions to test semantic caching
A frenzied race is underway across all industries to generate maximum value through GenAI and LLMs. It seems to be only a matter of time before providers like OpenAI or Anthropic are as integral in a tech stack as a database or server infrastructure. But as the dust settles and our applications become more reliant on the outputs of these models, new problems begin to emerge:
- their cost
- their inherent latency
- rate limited and unreliable APIs
Semantic caching is a tool at your disposal. The idea is simple: there are many different ways of asking a question to get the same answer. If you can understand the underlying meaning of a query, you can reuse a response to answer it. By mapping different prompts to existing responses you avoid making an unnecessary API call to your LLM provider, reducing your token usage and cutting the latency to almost zero.
I tested the use case of semantic caching by running an experiment using real world data - questions posed on the website Quora. I present an open-source tool for this called Semcache, which provides a caching layer between a client and an LLM API.
The dataset published by Quora contains actual questions posted on their website. For example “What is the most populous state in the USA?” and “Which state in the United States has the most people?”. Questions that are semantically equivalent, such as these, are marked as duplicates in the dataset. I like the use of this dataset because it is human and raw (have a look at some of the questions in there). They have spelling mistakes, incorrect grammar and many are generally idiosyncratic.
Summary of experiment
- Requests sent to a LLM API via Semcache
- Dataset: Quora Question Pairs - ~20,000 questions sent
- 28% cache hit rate (5,432/19,400 requests)
- 165x speed improvement (0.010s vs 1.648s average latency)
- LLM Model: claude-3-haiku-20240307
Setup
The experiment consists of three components: the client sending requests, the semantic caching proxy and the LLM API.
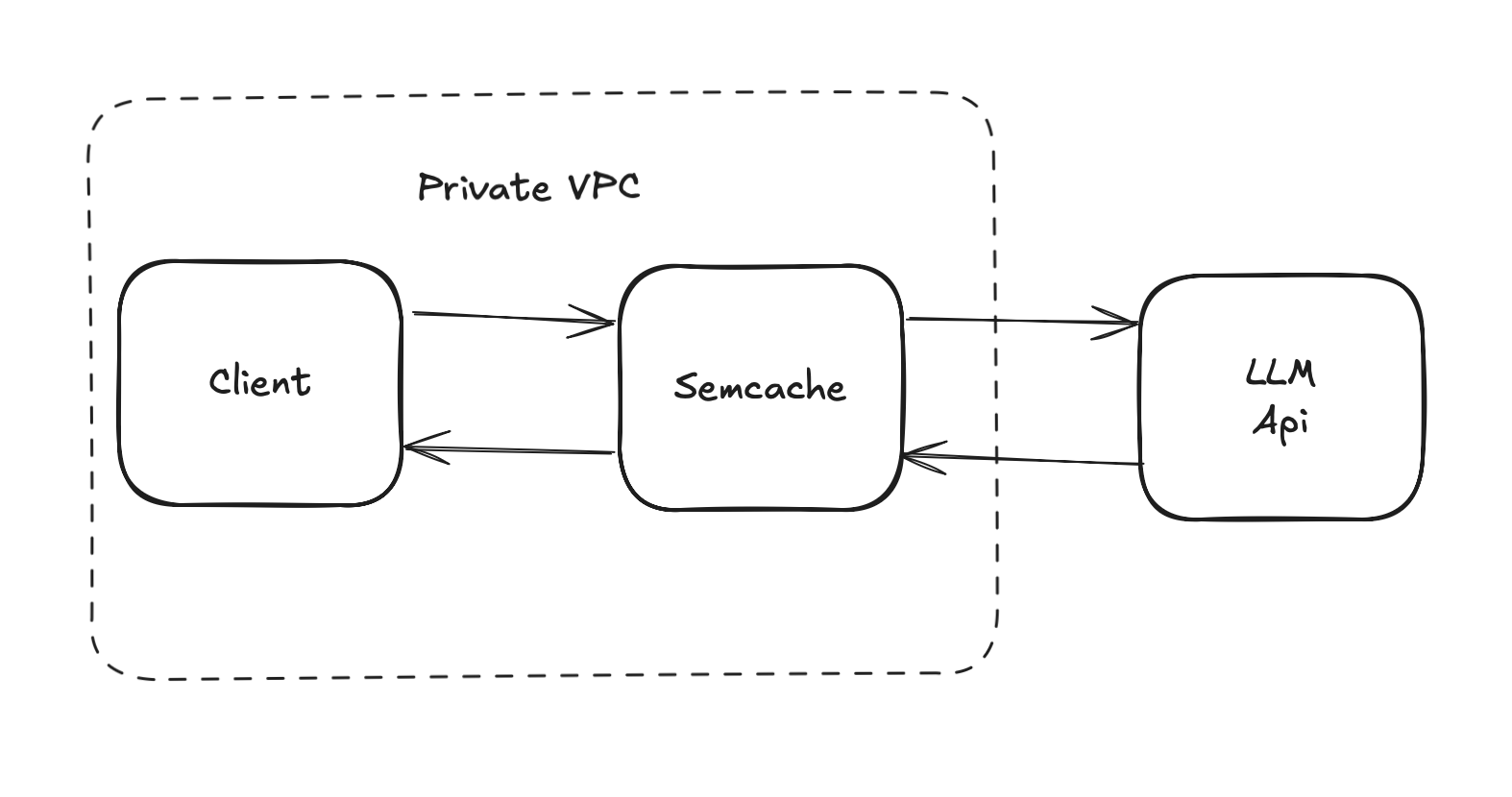
Semcache acts as a middleware layer between applications and LLM providers. It works as a drop-in HTTP proxy, which accepts requests from clients and forwards them to the LLM API. Semcache stores responses from the LLM API and returns them to the client. When a new request comes in it compares the embedding of the text to existing cached prompts. If the similarity is above the user set threshold it is considered a hit. The cache operates entirely in-memory and is cold at the start of the experiment - it is built up over time as requests are received.
We used Anthropic’s Python SDK to send the Quora questions and altered the base url to point to our Semcache instance:
self.client = AsyncAnthropic(
api_key=os.getenv("ANTHROPIC_API_KEY"),
base_url=semcache_host
)
Semcache was deployed on an AWS t2.micro EC2 instance (running on the free tier) with the benchmark client operating on a separate EC2 instance within the same network. The system used cosine similarity for comparing vector embeddings, with the similarity threshold set to 0.9. For text embedding generation the implementation used the sentence-transformers/all-MiniLM-L6-v2 model. The client is calling Anthropic’s claude-3-haiku-20240307 model for answers to its questions.
Results
Out of 19,400 total requests the system achieved a cache hit rate of 28.0%, serving 5,432 requests from the cache. The performance difference between hits and misses was substantial: cached responses were served with an average latency of just 0.010 seconds, while cache misses required an average of 1.648 seconds to process.
Semcache’s memory footprint grew from 160MB to 201MB after caching 5,494 unique prompt-response pairs. This works out to approximately 7.5KB per cached entry. Each entry includes a 384-dimensional vector embedding of the prompt, the entire response from Anthropic, metadata (timestamp, access count). This means a server with 8GB of RAM could theoretically cache over 1 million prompt-response pairs.
Accuracy challenge
Unlike traditional exact-match caching, semantic caching operates in a fuzzy domain where “similarity” is subjective and context-dependent. In this experiment we observed questions that were considered a cache hit by Semcache but were labelled as “non-duplicates” in the Quora dataset. Defining what should or shouldn’t be considered a cache hit is heavily dependent on the use case of the data. For instance Quora labels the questions below as non-duplicates whilst our system marked them as semantically equivalent:
- “What is pepperoni made of?”
- “What is in pepperoni?”
Now to me as a layman, both of these questions about the contents of spicy Italian sausage seem interchangeable. However clearly there is a definition that Quora is following that means they are not semantically equivalent.
We did observe some false positives in our cache hits that are more questionable. Such as the below example:
- “What is Elastic demand?”
- “How do you measure elasticity of demand?”
The challenge here is aligning the caching system to your application by altering the semantic similarity threshold and the text embedding model. The choice of text embedding model has probably the greatest impact. The sentence-transformers/all-MiniLM-L6-v2 model used here provides a good general model for semantic understanding, but domain-specific models are more likely to yield accurate results.
In the real-world
Semantic caching offers several practical benefits that make it worth implementing in production LLM applications. The most obvious is cost reduction. Fewer tokens sent to LLM providers means lower bills, which matters when you’re processing thousands of queries daily. This becomes even more relevant if you’re using AI orchestration tools that charge based on compute time. When your cached responses return in milliseconds instead of seconds, you’re paying for less execution time.
Perhaps most strategically valuable is the knowledge layer that accumulates over time. Each cached response becomes part of an organisational memory that’s completely agnostic to any specific LLM provider. During our experiment, Anthropic experienced service disruptions that forced us to throttle requests significantly. Applications with robust semantic caching layers can maintain functionality by serving cached responses.
Final thoughts
In our setup in this experiment we ended up with a hit rate of 28%, but depending on the source of your prompts this number can be a lot higher. The text embedding model, the similarity threshold, how to host your semantic caching infrastructure are all decisions that need to take into consideration your specific use case. Semantic caching proves itself to be a powerful tool to reduce token usage and latency, but it is not free of complications.
If you’d like to test out Semcache for yourself you can find it on Github: https://github.com/sensoris/semcache
Interested in learning more?
We’re currently beta testing our cloud-hosted version of Semcache, designed to eliminate the technical complexities of managing semantic caching infrastructure yourself. Instead of being concerned with semantic similarity, embeddings and persisting challenges you focus on building your LLM applications and use Semcache to reduce token usage and latency. Join our waitlist at https://semcache.io/waitlist or reach out directly at louis@semcache.io to get early access.